Jeff saura fait une étude sur des données de surveys et compare des researchers à Chat-GPT. https://measuringu.com/classification-agreement-between-ux-researchers-and-chatgpt/ Super intéressant et au final la conclusion, comme nombre d'articles sur le sujet est que c'est le MIX humain + AI qui fera le boulot. On va assister en fait à une éclosion de méthodes en UXR tournées sur l'analyse de sentiment, data et reviews, tout en rendant cela automatique. Et cela rafraichissant ! (Mais attention aux biais!!)
Alexis Gérôme
· Staff UX researcher
· il y a 2 ans
Un livre qui porte sur l'analyse de la culture de la silicon Valley ! Super intéressante et probablement la meilleure étude sur le sujet. https://www.sup.org/books/title/?id=27408
Il peut arriver de trouver des résultats qui ne sont pas homogènes. Très souvent ce phénomène s'explique par : des cibles sous-jacentes différentes par nature (génération, mindset, culture, besoins, maturité d'usage, habitudes d'achat, critères sociodémographiques etc.) des situations d'usages différentes lors du test des objectifs personnels d'usages différents lors du test des questions mal posées / comprises (et oui !) un paradoxe non résolu au plan analytique (c'est à dire que votre réfléxion doit encore s'aiguiser !) Lorsque le détail des réponses montre des différences significatives il est essentiel d'en comprendre la causalité ... dans ce cas, il faut retourner dans le détail des résultats pour traquer les sources possibles de ces différences, émettre des hypothèses et les valider (ou creuser encore) avec l'observation attentive des éléments précis de perception. Surtout, il est toujours nécessaire de prendre le temps de l'expliquer dans votre analyse. En effet, le lecteur / auditeur doit être guidé dans la complexité de certains résultats et on ne peut lui demander, même si cela apparait évident pour vous, de résoudre seul une "équation" non résolue. Ne laisser jamais trainer des résultats opposés / différents sans avoir pris la peine d'expliquer le pourquoi ! Dernier petit conseil bonus, lorsque que vous partez avec une étude impliquant des cibles potentiellement très hétérogènes, commencez par créer des personae (même si le but de l'étude n'était pas explicitement celui-ci), puis lorsque les résultats diffèrent, splittez votre chart en présentant la variété des données récoltées en fonction de ces différents profils de cibles et leurs logiques propres. Sabri
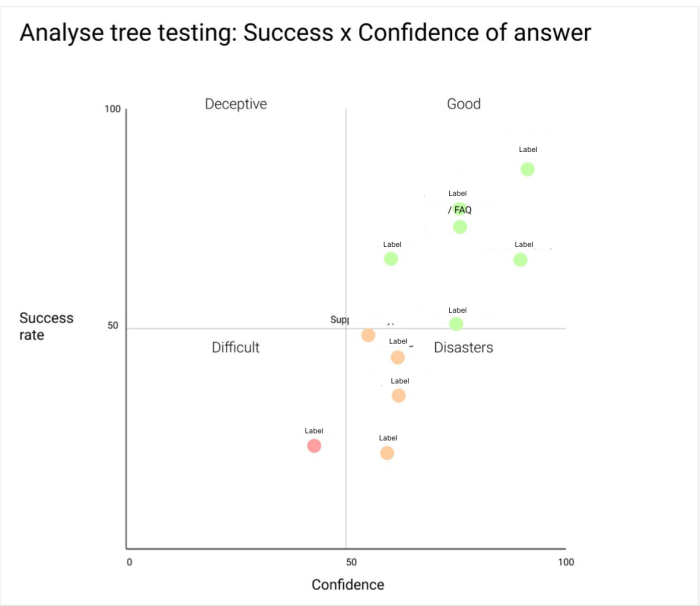
Cette semaine j'ai analysé un tree testing et j'ai trouvé ce framework de Jeff Sauro pour analyser et présenter vos findings: Sur un axe affichez le % de succès Et sur l'autre le degré de confiance des gens qui ont sélectionné les options. Cela requiert que vous demandiez à vos utilisateurs de noter leur degré de confiance après chaque tâche afin d'avoir ce résultat. Pour finir, vous avez cette carte qui est très impactante en termes de résultats, et parle d'elle-même. Effet garanti. Ensuite vous pouvez aussi comparer le taux de réussite global vs au premier clic. Très intéressant pour les menus déroulants, catégories à rallonges etc.. Comparaison au 1er niveau COMPARAISON AU 2eme NIVEAU
Alexis Gérôme
· Staff UX researcher
· il y a 4 ans
Si comme moi vous devez analyser plus de 10K de lignes excel provenant de tickets clients, voici un article qui peut vous aider et vous faire avancer plus vite dans l'analyse des données. https://www.andyfitzgeraldconsulting.com/writing/keyword-extraction-nlp/ Je vais essayer de mettre en place pour tester et apprendre, puis je ferais un rex le moment venu :)
Alexis Gérôme
· Staff UX researcher
· il y a 4 ans
Un groupe pour poser vos questions et partager vos astuces, ressources, outils, et actualités sur l'utilisation des sciences cognitives dans le monde produit.
Un groupe pour poser vos questions et partager vos astuces, ressources, outils, et actualités sur la green UX qui comprend l'éco-conception et la sobriété numérique.
Groupe pour partager les offres d'emplois, et de missions freelance en France ou ailleurs ainsi que de discuter de nos choix de carrières.
Postage libre aux professionnels UX. Pas de recruteurs/RH.




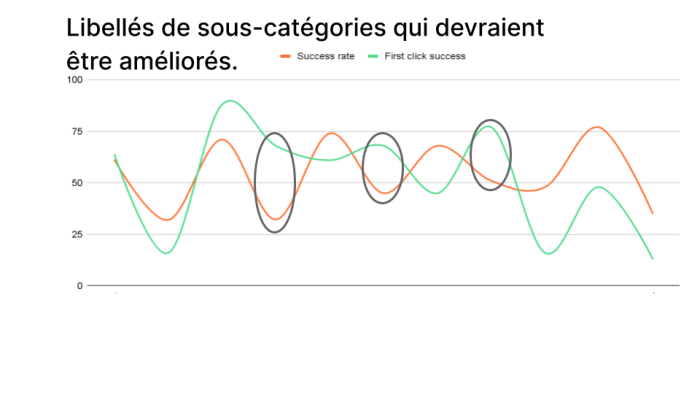
 Ensuite vous pouvez aussi comparer le taux de réussite global vs au premier clic. Très intéressant pour les menus déroulants, catégories à rallonges etc.. Comparaison au 1er niveau
Ensuite vous pouvez aussi comparer le taux de réussite global vs au premier clic. Très intéressant pour les menus déroulants, catégories à rallonges etc.. Comparaison au 1er niveau 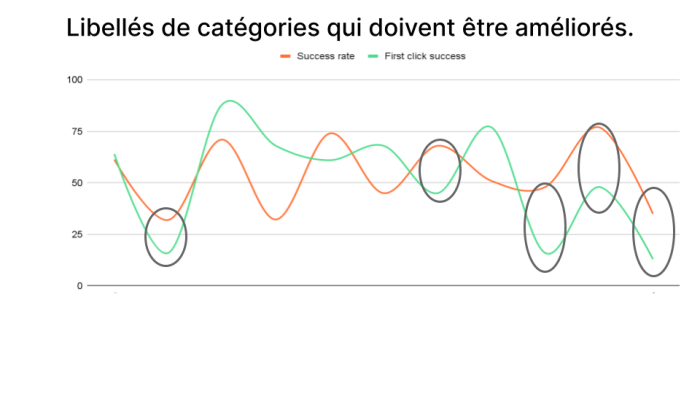 COMPARAISON AU 2eme NIVEAU
COMPARAISON AU 2eme NIVEAU