
ChatGPT, Gemini ou Agent GPT, quel LLM* performe le mieux sur un sujet de recherche?
4 LLMs, un même prompt, des résultats mitigés
Vous l’avez sans doute remarqué, Gemini a fait une entrée tonitruante sur le marché des LLMS, et se positionne en concurrence directe avec ChatGPT. Curieuse de voir ce qu’il avait dans le ventre, j’ai décidé de faire un test simple: comparer les résultats sur un sujet de recherche hypothétique mais réaliste. Quel LLM saura me donner une réponse satisfaisante (correcte, exhaustive, précise) et saura réellement me servir de partenaire dans mes activités de brainstorming?
J’ai sélectionné 4 LLMs pour cet exercice comparatif: ChatGPT, Gemini et Agent GPT, et Perplexity tous en version gratuite.
Mon choix s’est porté sur ces LLMs suite à plusieurs articles qui ont inondés ma boîte mail au lancement de Gemini. Ma curiosité était piquée, je devais savoir ce que la bête avait dans le ventre. Ayant déjà expérimenté avec ChatGPT et AgentGPT, je souhaitais comparer leurs performances. En ce qui concerne Perplexity, c’est un article de Jakob Nielsen publié en novembre 2023 (une éternité dans le monde de l’IA), qui m’a poussée à l’intégrer à cette expérience.
Mon expérience s'est articulée autour d'un prompt commun : élaborer un plan de recherche sur un sujet de maîtrise, simulant la démarche d'un UXR cherchant à identifier les besoins d'une marque dans le cadre d'une solution SaaS pour les RH, questionnant l'existence d'un marché pour une telle solution développée par une entreprise. Notez que mon prompt était plutôt vague, il n’y était pas question du marché visé, ni de la marque, encore moins du type de produit SaaS. Aussi le prompt utilisé me laissait imaginer que les résultats ne pourraient être que très génériques.
Voici le prompt utilisé:
Act as a UXR who needs to uncover the specific needs of a market, when it comes to SaaS solutions for HR. Write a research plan. The main research question being: is there a product market fit for a specific solution, developed by a foreign company. Also rephrase this prompt for better result.
Agis comme un UXR qui doit découvrir les besoins spécifiques d'un marché en ce qui concerne les solutions SaaS pour les RH. Rédige un plan de recherche. La principale question de recherche étant : existe-t-il un adéquation produit-marché pour une solution spécifique, développée par une entreprise étrangère ?
Une astuce personnelle que j'ai employée consiste à demander à ces modèles de reformuler le prompt pour optimiser les résultats, une technique souvent couronnée de conseils utiles pour mieux exploiter l'outil.
Score global

Les résultats de recherche sont assez comparables (voirs les détails ci-dessous). En ce qui concerne l'interface, les modèles comparés sont assez accessibles pour un utilisateur novice, à l'excéption de AgentGPT, dont la prise en main peut s'avérer moins aisée. On retrouve le ton et style de communication assez mécanique de ChatGPT dans la plulart des modèles. Gemini semble un peu moins formel, et se démarque légèrement en la matière, mais de très peu. AgentGPT se caractérise par une répétition de tâches sous formes de listes numérotées, et un contenu moins "conversationnel" que ces concurrents. En ce sens, il se détache du lot et peut paraître moins convivial.

1 des 6 tâches détaillées par Agent GPT
Les résultats obtenus de Gemini et ChatGPT étaient étonnamment similaires en termes de contenu, couvrant les objectifs, la cible, les méthodologies mixtes (quantitative et qualitative), le plan, les ressources, et les questions de recherche. Cependant, Gemini se distingue par une formulation légèrement plus naturell, moins mécanique que celle de ChatGPT.
Intéressant à noter, Gemini m’a livré 3 propositions: la première est assez semblable à celle de ChatGPT, la seconde, intéressante, différencie Market, User Research, et Data Analysis. Quant à la troisième version, elle propose une refonte du prompt et un focus fortement accès sur la recherche de marché:
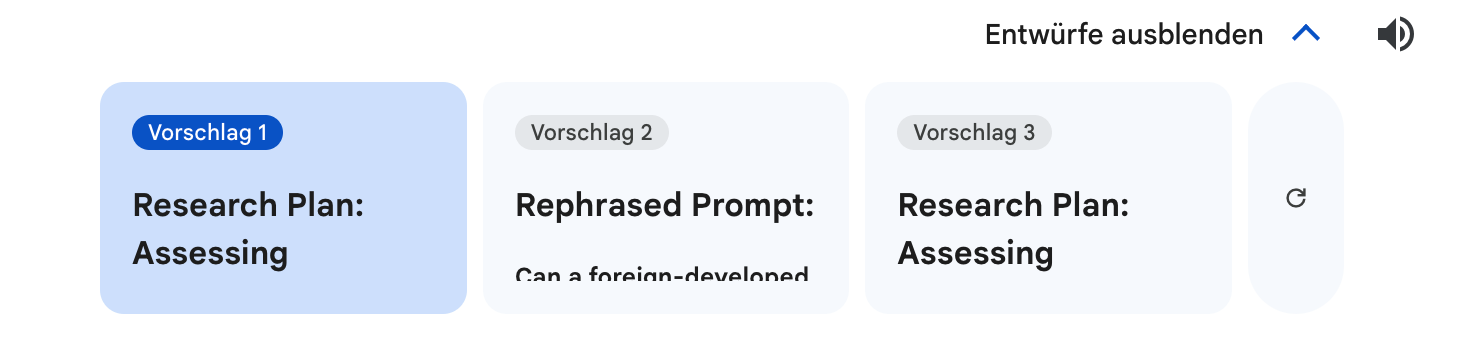
3 résultats de recherche suggérés par Gemini
“Rephrasing the Prompt:
Instead of focusing solely on the "foreignness" of the company, let's rephrase the prompt to emphasize the solution itself and its potential fit in the market:
Main Research Question: Does the proposed HR SaaS solution, developed by [Company Name], address the unmet needs and pain points of its target audience within the HR market?”.
Dans sa première proposition, Gemini énonce des livrables et une timeline détaillée des activités de recherche semaine par semaine, ainsi que des conseils sur les plateformes et logiciels à utiliser pour la collecte et l'analyse des données. C’est un peu plus que ce que propose ChatGPT, mais il me semble difficile d’avancer un planning du projet sans la moindre connaissance du contexte, des ressources et des contraintes inhérentes au projet.

Il met également en lumière l'importance de considérer les différences culturelles dans les méthodes de recherche, et la confidentialité des données, un point que ChatGPT n'a pas abordé. En ce sens, et malgré des résultats très semblables à ChatGPT, il offre une dimension différente, moins cadrée, en s’éloignant légèrement du prompte initial, qui ne mentionnait pas les facteurs et contraintes à prendre en compte.

AgentGPT, quant à lui, propose un plan de recherche complet et des tâches spécifiques pour chaque étape de recherche proposée. Cependant, sa version gratuite est limitée à cinq interactions. Dommage, car j’aurai bien aimé voir la suite. Chaque “tâche” est détaillée et présente une liste numérotée d’actions à prendre. Ceci me semble, dans ce contexte, la version la plus intéressante, à défaut d’être exhaustive et pertinente (le prompt était trop vague pour permettre une réponse réellement adaptée).
Enfin, le plan de recherche proposé par Perplexity en 6 grands points n’apporte réellement rien de nouveau. En ce sens, le plan de recherche me semble peu utile. Ce qui peut s’avérer intéressant ceci dit, sont les références aux sources (sans doute utilisées par les autres LLMs) et la section “Related” qui propose d’autres questions pour étendre son axe de recherche.
L’ajout d’une nouvelle section permettant de chercher les vidéos ou images en lien avec le sujet peut permettre une recherche plus efficace, dans la mesure où Perplexity pointe vers du contenu utile. Ce serait idéal si le contenu était réellement pertinent: sur les 4 vidéos proposées, les ¾ n’étaient qu’indirectement en rapport avec mon sujet.

Section “Sources” dans Perplexity

Section “questions ou recherches associées” dans Perplexity
Conclusion
Dans l’essence, malgré des approches et des présentations différentes, tous les modèles testés se rejoignent en terme de contenu. Certains sont plus “aventureux” dans leurs résultats (notamment Gemini). AgentGPT se démarque par ses résultats itératifs, qui peuvent apporter une grande granularité. Pour les débutants en UXR, ces outils peuvent s'avérer utiles pour surmonter les limitations liées au manque d’expérience et structurer leurs démarches de recherche, mais ils ne sauraient remplacer une démarche de définition du champ de recherche préliminaire. Si je devais opter pour un partenaire de brainstorming, mon choix se porterait sans doute sur AgentGPT, mais je crains que la version gratuite ne soit limitée. Un investissement s’impose donc, pour en faire un vrai outil de travail. Il est aussi de loin celui à l’interface et la prise en main la moins intuitive.
Gemini semble aller un peu plus loin dans la “réflexion” sur un prompt qui ne prend pas en compte les spécificités du projet, de l'industrie, ou des parties prenantes. Je trouve les 3 résultats intéressants, et n’exclue pas, à l’avenir, de comparer les résultats d’un même prompt entre ChatGPT et Gemini.
Quant à Perplexity, je l’utiliserait principalement pour retrouver les sources des résultats et pour des recherches au périmètre très précis. L’avenir nous montrera peut-être que l’un ou l’autre s’avère plus efficace pour ce type d’exercice, mais pour l’heure, je suis d’avis qu’il s’avère d’explorer et d’exploiter la diversité de ces ressources, tout en sachant faire preuve d’esprit critique.
Attention
Dernier point et pas des moindres, n’hésitez pas à réitérer votre prompt et à comparer les résultats à quelques heures ou jours d’intervalle dans chaque LLM, dans la mesure où il y a de fortes chances s’obtenir des résultats différents.
Ceci est due à la nature non déterministe des LLMs (il n’y a aucune garantie de consistance), qui permet aussi de regénérer une réponse, si l’on n’aime pas le résultat initial. Cela veut aussi dire que la même recherche, dans le même LLM, à une heure d’écart, peut donner des résultats différents, le modèle cherchant à donner le résultat le plus probable à l’instant T.
Ceci est pour moi un très bon rappel de la nature même de ces modèles d’ IA générative: les comprendre c’est mieux les prompter et les appréhender avec recul et sens critique. La qualité des résultats dépendra largement de la qualité du prompt et de la précision apportée. Cet article en Anglais livre quelques pistes intéressantes pour limité la propriété aléatoire des résultats de recherche.
*Large Language Model: voir définition sur Wikipédia
